Generated GraphQL API for Salesforce
📣 Here is a small announcement before diving into this post, Salesforce is currently working on an official GraphQL endpoint. As of this writing, Salesforce hasn’t yet released any public documentation. That said, the official GraphQL endpoint is quite similar to the one presented in this post, with some other nice features 🎉. You can contact Ben Sklar if you would like to try it out.
Back in 2016 Robin Ricard and I presented at Dreamforce a talk about how to leverage GraphQL to query Salesforce data (recording). For this presentation, we built a demo application for browsing your favorite movies. The data was stored on Salesforce as custom objects. This was built on React native to retrieve the data by the intermediary of a GraphQL endpoint hosted on Heroku.
For this demo, we had to handcraft a GraphQL schema and hardcode SOQL queries to retrieve the data on our Salesforce org. This approach works great for a demo application, but is unmaintainable in complex applications:
- ensuring that the GraphQL schema is always in sync with the Salesforce schema is painful
- exposing new types on the schema requires adding new SOQL queries or updating the existing ones
- no out-of-the-box support for filtering and sorting
The GraphQL ecosystem is moving fast, and a lot happened over last 5 years. We have seen a proliferation of tools making its adoption easier. I am amazed how easy it is today to create a GraphQL API. Projects like PostGraphile or Hasura GraphQL Engine generates a GraphQL endpoint on top of a SQL database with minimal configurations. Those tools connect to the database of your choice (eg. Postgres, MySQL) and generate a GraphQL API based on the DB schema.
Taking a step back, Salesforce is a database under steroids. If we are capable to generate GraphQL APIs on top of industry-standard databases, could we replicate this with Salesforce? Is it possible to generate a GraphQL API based on the Salesforce schema?
During the winter break, I started working on a prototype of such a service. The source code is located at pmdartus/sfdc-graphql-endpoint. In the rest of this blog post, I will present at a high level how this service works, how to generate a GraphQL schema from Salesforce metadata, and finally how to efficiently query Salesforce APIs to resolve GraphQL queries.
📝 In case you need a refresher on GraphQL, I would recommend you to look at the GraphQL official documentation. The awesome-graphql list also contains a bunch of interesting projects articles on this topic.
Overview
At a high level, the GraphQL server is a standalone application server sitting between the client (a web app, a mobile app or, another server) and a Salesforce org. This server can be hosted on Heroku or any other cloud provider. This service exposes a single HTTP endpoint /graphql. The endpoint accepts graphQL queries over GET and POST requests.

After starting the app, the server retrieves the Salesforce org metadata to build a GraphQL schema. The schema is currently cached in memory for the entire life-time of the application. Once done, the server can start processing GraphQL queries. The incoming queries are validated against the GraphQL schema, and resolved by querying Salesforce via the REST APIs.
Generating a GraphQL schema using Salesforce metadata
Schema is a core concept of GraphQL. It defines the data model exposed by the endpoint. Typically the schema is defined via the schema definition language (SDL). It is a textual representation of the data model.
type Actor__c {
Id: ID
Name: String
}
type query {
Actor__c_by_id(id: ID): Actor__c
}The schema is used for various operations at runtime. This includes query validation, response validation, and schema introspection. In our case, we will need to map Salesforce entities to GraphQL types.
Defining the GraphQL schema via the schema definition language works well whenever dealing with a static schema. SDL is not well suited for our use case where the GraphQL schema is dynamically generated. An alternative approach is to generate the schema programmatically via graphql/type module.
The SObject metadata can be retrieved using the describeSOjbect REST API. It returns a complete description of an entity including the fields and relationships.
Each SObject can be represented via a GraphQL object types. SObject fields types can be grouped into 2 buckets: scalar fields and relationship fields.
- GraphQL comes with a predefined list of scalar types. Scalars represent leaf values in the graph. This list includes:
Int,Float,String,Boolean, andID. However, Salesforce offers a lot more field types, eg.Date,Phone, orCurrency. Fortunately, GraphQL allows the definition of custom scalar. A custom GraphQL scalar type can be created for each of the missing Salesforce scalar field types. - GraphQL type system allows defining fields referring to other GraphQL object types in the schema. Salesforce lookups and master-detail relationships can be represented in GraphQL by creating a field and setting its type to the associated GraphQL object type.
Finally, the GraphQL schema should define a Query type. This type defines the entry points into the graph. For each exposed SObject, we generate 2 fields the Query type:
- a field named
[SObject_name]_by_idreturning a single record. This field accepts a requiredIDargument. - a field named
[SObject]returning a list of records. This field accepts optional arguments limit, filter, and order the list.
Here is an example of a Salesforce schema and its generated GraphQL schema.
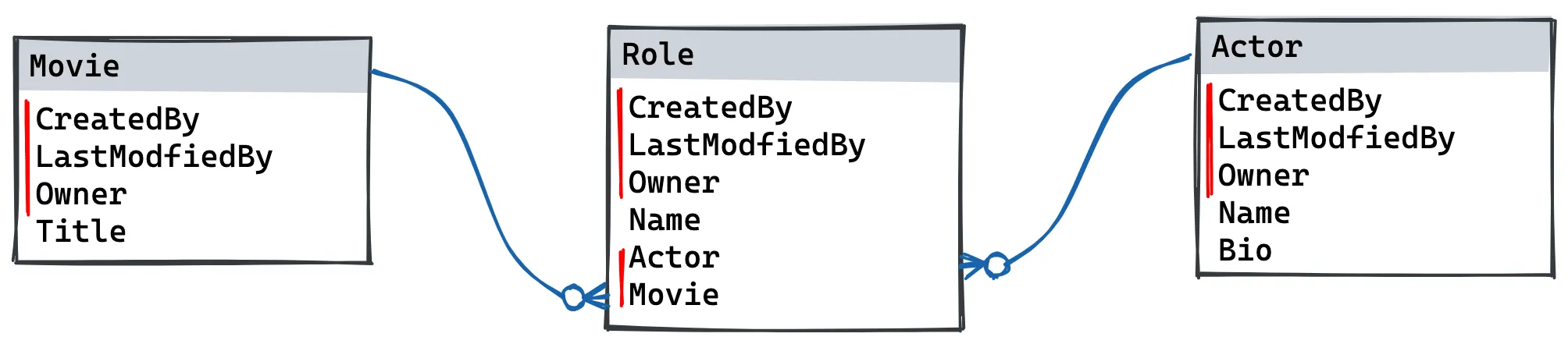
scalar TextArea
type Movie__c {
Id: ID!
Name: String
Roles__r: [Role__c]
}
type Role__c {
Id: ID!
Name: String
Actor__c: Actor__c!
Movie__c: Movie__c!
}
type Actor__c {
Id: ID!
Name: String
Bio__c: TextArea
Roles__r: [Role__c]
}
type Query {
Movie__c(
limit: Int
offset: Int
where: Movie__cWhere
order_by: [Movie__cOrderBy]
): [Movie__c]
Movie__c_by_id(id: ID): Movie__c
Role__c(
limit: Int
offset: Int
where: Role__cWhere
order_by: [Role__cOrderBy]
): [Role__c]
Role__c_by_id(id: ID): Role__c
Actor__c(
limit: Int
offset: Int
where: Actor__cWhere
order_by: [Actor__cOrderBy]
): [Actor__c]
Actor__c_by_id(id: ID): Actor__c
}The source code for the GraphQL schema generation can be found in src/graphql/schema.ts and src/graphql/types.ts.
The N+1 query problem
Now that we have a better idea of how to generate the GraphQL schema, let’s dive into the actual query execution.
After being validated against the schema, a GraphQL query is executed by the GraphQL server. The GraphQL server relies on functions called resolvers to execute a GraphQL query. The resolvers are functions that can be attached to any field on the schema. The function is in charge of retrieving the data for its field. The GraphQL execution will keep going until all the fields for the query are resolved.
One of the main performance bottlenecks with GraphQL is the N+1 query issue. GraphQL queries usually involve joining multiple tables when accessing nested data. Let me give a concrete example to illustrate this.
query {
Actor__c {
# retrieve actors (1 query)
Name
Bio
Role__r {
# retrieve the roles for each actor (N queries for N actors)
Name
}
}
}In the case above, the server needs to do 1 request to Salesforce to retrieve all the actors. Subsequently, the server needs to make N requests to Salesforce to retrieve the actor’s roles for the N actors. This approach leads to N+1 roundtrips to Salesforce to resolve the GraphQL query. If there were 50 actors, the server would need to issue 51 queries to Salesforce. As you can imagine, this is not viable as the number of requests needed grows exponentially with the depth of the query.
A common answer to the GraphQL N+1 problem is to use batching. Instead of fetching each role independently, the roles for all the actors could be fetched in a single roundtrip by combining all the requests into a single one. Utilities like DataLoader help you achieve this.
Transforming GraphQL queries to SOQL
Great we are making progress, from 51 requests are now down to 2 requests to Salesforce to resolve the GraphQL query. That said, we can optimize this further by changing the approach we are taking for data fetching. Instead of making several roundtrips, we can compile the GraphQL incoming query as a SOQL query. This approach allows resolving data at any depth with a single SOQL query.
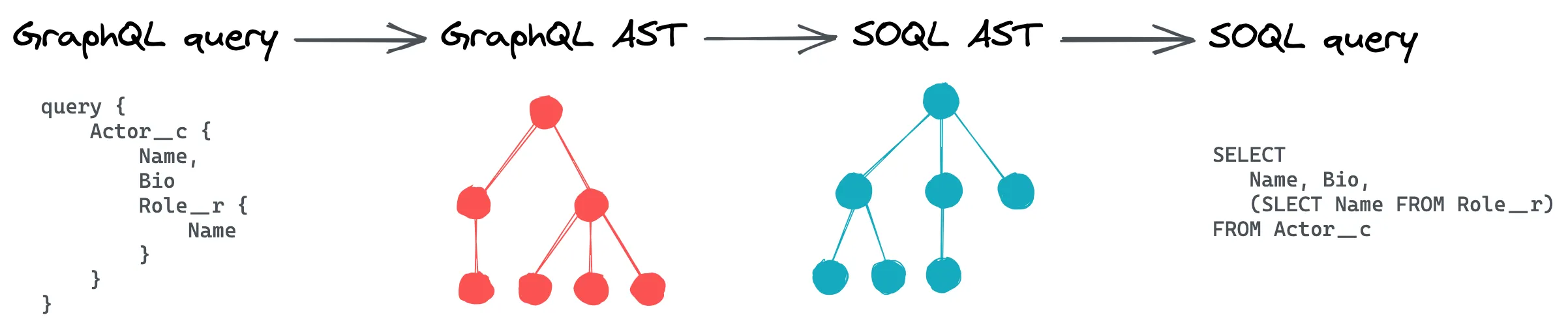
GraphQL queries are parsed and transformed into an in-memory representation called abstract syntax tree (AST). All programming languages can be represented as an AST format, including GraphQL and SOQL. The GraphQL AST can then be turned into a SOQL AST with the help of the previously generated schema. Then the SOQL AST is serialized to a SOQL query before being sent to Salesforce.
The code related to SOQL AST generation and serialization can be found under src/graphql/resolvers.ts and src/sfdc/soql.ts.
Processing the SOQL query result
The Salesforce Query REST API endpoint, executes a SOQL query and returns an array of records. Prior sending the GraphQL response, the service transforms the record array to match with the GraphQL schema. Luckily, the SOQL response shape is quite similar to the GraphQL schema, with record lookups represented as nested objects in the response.
The GraphQL resolvers can be used to map the SOQL response to GraphQL response. Those resolvers are assigned to each GraphQL object type field during schema generation: scalar resolver, lookup resolver, and master-detail relationships resolver.
Closing words
I am quite excited by the new capabilities GraphQL has to offer. I can foresee it changing the way developers build applications on top of the Salesforce platform. By embracing a standard API language, developers will be capable to leverage projects and tools created by the GraphQL community.
This proof-of-concept is far from being production-ready. It is missing some key features including authentication/authorization, object/field-level security, polymorphic relationships support, and mutation. But it’s a good starting point.
As a follow-up, I am interested to see how the generated GraphQL schema could be extended to incorporate custom logic. For example, extending generated GraphQL objects with custom fields baked by Apex and Salesforce functions. Another interesting idea worth exploring is how schema stitching could be used to query multiple GraphQL services.